Introduction
Clustering Algorithms is one of the types of algorithms of Unsupervised Machine Learning. Unsupervised learning uses unlabelled data. That’s why unlike supervised machine learning algorithms, cluster algorithms use unlabelled, divide the dataset into natural several groups on the basis of similarities of characteristics.
Types of Clustering Algorithms
Clustering is a subset of unsupervised machine learning algorithms, which contains several techniques or algorithms. And here one of the top most clustering algorithms are given below:
- K-means Clustering
- Hierarchical Clustering
- Fuzzy C-means Clustering
#1 K-Means Clustering
K-Means Clustering is one of the simplest and frequent algorithms of unsupervised learning, where K can be defined as the targeted number of clusters within the whole dataset and the centroid is considered as the imaginary or real location representation of centre of the cluster, where a cluster refers to a group of datapoints having certain similarities.
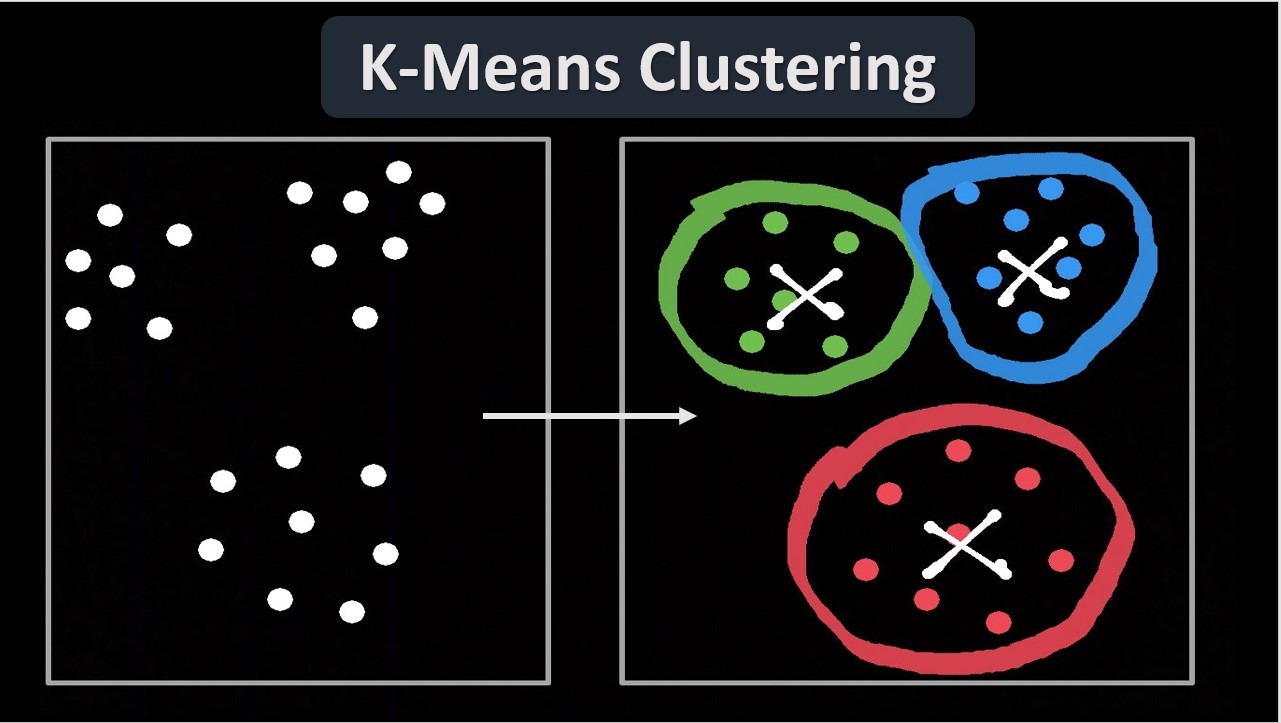
First of all, the algorithm begins with the first cluster from randomly selected clusters, these are used as starting or initial points for all clusters and then it performs repetitive or iterative manipulations to optimise the centroids’ locations.
#2 Hierarchical Clustering
Hierarchical clustering analysis is a technique that groups similar data-points or objects into groups or also called as clusters. In hierarchical clustering, we assign each object to a separate cluster. It computes the distance between each of the clusters and join them with the most similar clusters.
there are two types of methods to perform Hierarchical Clustering:
- Agglomerative Clustering: Agglomerative Clustering or AGNES (Agglomerative Nesting) is a top-down clustering method. In this kind of clustering process, we start from a single-element cluster (leaf). After each step, two similar clusters are combined into a new big cluster (nodes). This process continues itself until all data points do not become member of a single huge cluster.
- Divisive Clustering: Divisive Clustering or DIANA (Divisive Analysis) is a bottom-up clustering method. In this kind of clustering process, algorithm follow an inverse order of AGNES. It begins from the root and does not stop until it does not get single-element clusters.
#3 Fuzzy C-Means Clustering Algorithm
Fuzzy C-Means Clustering is an unsupervised machine learning algorithm which allows one piece of data belong to more than one cluster. In layman terms, one data is a member of its neighbouring clusters but with a certain degree known as membership value. This clustering method or algorithm was developed by Dun in 1973, and improved by Bezdek in 1981. This method is mostly used in pattern recognition method.
Applications of Clustering
- Recommendation engines
- Market or Customer Segmentation
- Social Network Analysis
- Search Result Clustering
- Biological Data Analysis
We will discuss these concepts in a broad way within upcoming blogs.
Powered by Froala Editor



