What is Data Science?
Data science is an inter-disciplinary field which is the combination of three domains, computer science, Business or domain expertise and Math & statistics. There are other skills too, which can be considered but most of the skills are covered through these three disciplines. There are some other sources which describes data science as the combination of specialized statistics, data analytics or business analytics and machine learning. We can observe the same from the following Venn diagram.
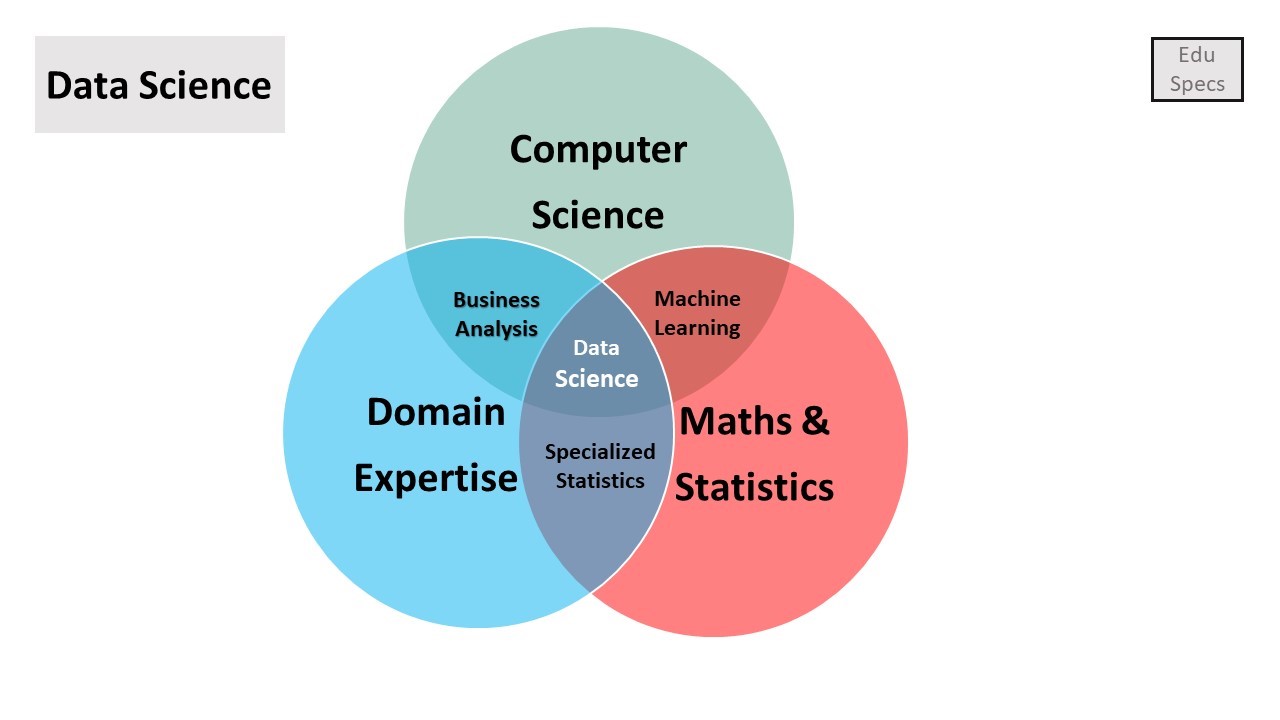
Data science have a lot of application within various fields such as Amazon and Netflix recommendations, recognition systems (image, text, video, audio, face detection), fraud detection, predictions, insights visualization, forecasting (weather, sales, revenue) and spam e-mail detection.
Data Science Life Cycle

1. Problem Understanding
Whenever we start a project within any company or team, we should have enough market understanding of various industries. It can be of Financial services, Information technology (IT), Investment Banking (IB), Financial Technology (FinTech) and Health industry etc., but why does this market understanding seem so mandatory? Because, it is essential to understand its objectives and problems. And for that we should know enough about our respective market industry and its problems.
Problem understanding is among one of initial stage of data science life cycles. Without problem understanding, all of the insights are useless because you should know what you are doing, and the aim behind data analytics and prediction or forecasting.
For example: you are working in Netflix as a data scientist (OTT platforms), and a dataset is given to you, and you have to compare your company to other companies (who are your competitors within the same market), you also have to find out market share of the company, its revenue, hidden data patterns. So, basically, you know that in which industry your working, and you are familiar with its competitiveness and problems.
2. Data Understanding
Data understanding is the step in which you do data collection from various sources, it can be surveys, datasets from any company or team or people and websites, who do research or provide respective market data. We should know about which kind of datasets we should collect. It must be relevant to your problems or objectives.
After Data Collection, we proceed towards Exploratory Data Analysis (EDA), we do find out features, correlation between variables, data types (numerical and non-numerical), its structures and many other information through visualization tools (matplotlib & seaborn, Tableau, Power BI and R).
3. Data Preparation
After Data Understanding step, the next step within Data Science Life Cycle is Data Preparation. It mainly consists three steps:
1. Data Wrangling: It includes steps like selecting the relevant data, integrating the data by merging the data sets, cleaning it, handling the missing values by either removing them or imputing them with relevant data, treating erroneous data by removing them, also check for outliers and handle them.
2. Feature Selection: This is a selection process of subset of input features from the dataset. This process is primarily focused on removing non-informative or redundant predictors from the model.
Two types of feature selection:
Unsupervised Learning: do not use target variable (unknown targeted variable)
- Correlation
Supervised Learning: use the target variable
- Wrapper: Search for well-performing subsets of features
- Filter: Select subsets of features based on their relationship with the target.
- Intrinsic: Algorithms that perform automatic feature selection during training.
3. Feature Engineering:
Feature engineering is the process transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.
So, we do feature selection and feature engineering in which we select or transform raw data into featured data-sets, which helps us to find out relevant features and prepare a data set for descriptive and predictive analytics.
4. Algorithm Selection
Algorithm selection and evaluation process is known as the heart of data analysis. It includes choosing an appropriate statistical algorithm or machine learning algorithm on the basis of its input and output data-types (which we get after data understanding and data preparation processes). We should choose an appropriate model, it can be regression, clustering, or classification models based on problems.
After choosing the model, amongst the various algorithms present. We need to tune a hyper parameter of each model to achieve the desired performance.
5. Evaluation
Last step of machine learning cycle, and second last step of data science life cycle, Evaluation is the process in which we evaluate the model or algorithm by its accuracy or efficiency and checkout the relevance with the problem or its solution.
Where accuracy talks about the performance of machine learning algorithm or model for the given prepared data set. And, Relevance step checkout that the insights came from the project are relevant or not and answer the problem or not.
We should also have focus on performance and generalizability. We need to make sure that there should be a correct balance between performance and generalization, which refers that the created model is biased towards any side.
6. Deployment
Most of the people think that Data Modelling and Evaluation is the final stage of Data Science Life Cycle, but that’s not the truth. There is one more step, which is known Deployment. The concept of deployment in data science refers to the application of a model for prediction using a new data. In this process we use machine learning model into an existing productive environment to make practical business decisions based on the data.
We should also focus on above steps (Data Understanding, Data Preparation, Algorithm or model selection and evaluation), because it seems a primitive thing to do this step but any type of error can create a huge difference due to this last process.
Powered by Froala Editor



